 Avoid pit
Avoid pit
Tips
There is an old saying, "If a worker wants to do a good job, he must first use a sharp tool", "Sharpen a knife without accidentally chopping wood"...
In order to let every user (especially Xiaobai) try to avoid stepping on pits and save more time, hereby summarizes a guide to avoid pits. Before officially using EE, you might as well spend three or five minutes to learn it, which can help you avoid pitfalls in use. Step on the pit, thus saving a lot of time. When encountering a problem, try to start from the standard of use and whether the version is compatible. The APIs we have provided are covered by test cases, and the single test coverage rate is as high as 95%+, and there are a large number of users in the community and the production environment. yes, don't do it Keyboard warriors, sprayers, when I came up, I felt that the framework was full of bugs, all kinds of sprays, in fact, it was my own dish... Either I didn't read the documentation and used it blindly, or the ES foundation was too poor and stepped on the pit of ES .In fact, such users do not help their own technical growth at all, The correct posture should be used according to the document specifications, and if you encounter problems, debug first, look at the source code, ask Du Niang, etc. If you can't solve it, you can join our Q&A group and we will help solve it. If it is confirmed as a defect, the Block level defect i They will be repaired within 24H, and other level defects will be solved and avoided immediately, and will be released as soon as possible.
In addition, if you encounter problems during use, you may wish to look for the answer from Faq. If not, you can join our Q&A group through the Join Community Discussion on our official website, and we will arrange Special personnel will help you answer free of charge, but try not to ask some 100,000 whys, everyone's time is precious!
# ES version and SpringBoot version
Because our bottom layer uses the official RestHighLevelClient of ES, we have requirements for the ES version. The ES and RestHighLevelClient JAR dependent versions must be 7.14.0. As for the es client
It is tested that any version of 7. X is compatible
It is worth noting that, due to the existence of SpringData ElasticSearch, Springboot has built in versions that depend on ES and RestHighLevelClient, which leads to the actual introduction of ES and RestHighLevelClient by different versions of Springboot
The versions are different, and the compatibility between the two official ES dependencies is very poor, which further causes many users to be unable to use Easy Es normally and complain that our framework is defective. In fact, this is a problem of dependency conflicts
We have done dependency verification when the project is started. If your project is started, you can see on the console that the printed level is Error, and the content is "Easy Es supported elastic search and restHighLevelClient jar version is: 7.14.0, Please resolve the dependency conflict!"
In the log, it indicates that there is a dependency conflict to be resolved
The solution is simple. You can configure Maven's exclude as follows to remove the ES and RestHighLevelClient dependencies declared by Springboot or Easy Es, and then reimport them. When importing, you can specify the version number to 7.14.0
<dependency>
<groupId>cn.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>1.1.0</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</exclusion>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.14.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.14.0</version>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
If you are a skittish lazy person, you can also simply and roughly adjust the spring boot version to 2.5.5. You don't need to adjust anything else, but you can also barely use it normally
##Keyword type and text type of ES index
If you already know the ES index type, you can skip this introduction directly.
The keyword type in ES is basically the same as the field in MySQL. When we need to perform exact matching, left fuzzy, right fuzzy, full fuzzy, sorting aggregation and other operations on the query field, the index type of the field needs to be keyword type. Otherwise, you will find that the query does not find the desired result, or even reports an error. For example, APIs commonly used in EE, such as eq(), like(), distinct(), etc., all require the field type to be keyword type.
When we need to perform word segmentation query on a field, we need the type of the field to be text type, and specify the tokenizer (use the ES default tokenizer if not specified, the effect is usually not ideal). For example, the API match() commonly used in EE, etc. The field type needs to be text type. When the expected result is not queried when using the match query, you can check the index type first, and then check the tokenizer, because if a word is not separated by the tokenizer, the result cannot be queried.
When the same field, we need to use it as both the keyword type and the text type. At this time, our index type is the keyword_text type. In EE, you can add the annotation @TableField(fieldType = FieldType.KEYWORD_TEXT to the field) ), so the field will be created as a keyword+text double type as shown in the figure below. It is worth noting that when we query this field as a keyword type, ES requires the incoming field name to be "field name.keyword" , when querying the field as a text type, you can directly use the original field name.
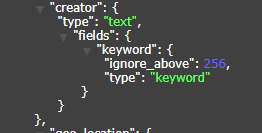
Another way is, you can redundant a field, the value is the same, one annotation is marked as keyword type, the other is marked as text type, and the corresponding field is selected according to the rules for query when querying.
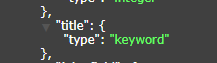
It should also be noted that if the index type of a field is created to query only the keyword type (as shown in the figure below), you do not need to append .keyword to its name, and you can query it directly.
# field id
Since many functions of the framework are implemented with the help of id, such as selectById, update, deleteById..., and there must be a column in ES as the data id, we force the entity class encapsulated by the user to include the field id column, otherwise the framework will not Some functions cannot be used normally.
public class Document {
/**
* The unique id in es, if you want to customize the id provided by the id in es, such as the id in MySQL, please specify the type in the annotation as customize or specify it directly in the global configuration file, so the id supports any data type)
*/
@TableId(type = IdType.CUSTOMIZE)
private String id;
}
2
3
4
5
6
7
If the @TableId annotation is not added or the annotation is added but the type is not specified, the id defaults to the id automatically generated by es.
When calling the insert method, if the id data does not exist in es, the data will be added. If the id data already exists, even if you call the insert method, the actual effect is to update the data corresponding to the id. This needs to be distinguished from MP and MySQL.
# Use Mybatis-Plus and Easy-Es at the same time in the project
In this scenario, you need to put the mapper of MP and the mapper of EE in different directories, and configure their own scan paths when configuring the scan paths, so that they can coexist, otherwise the two will be used when SpringBoot starts. Both scan the same path and try to register as their own beans. Since the underlying implementation depends on completely different classes, one of them will fail to register and the entire project will not start normally. Refer to the following figure:
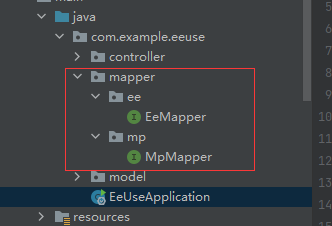
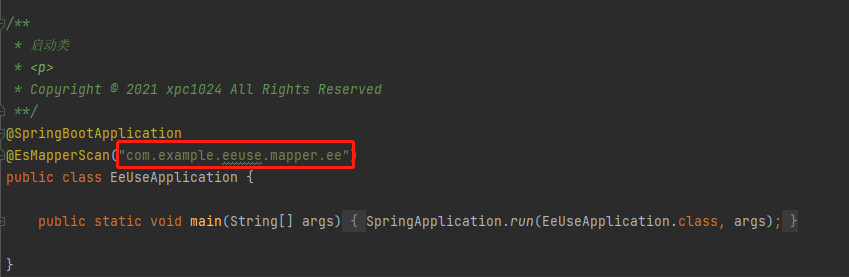
# and & or
It needs to be different from MySQL and MP, because the query parameter of ES is a tree data structure, which is different from MySQL tiling. For details, please refer to the Conditional Constructor-and&or chapter for detailed savings
I will talk so much about avoiding pits for the time being. If there are any supplements, I will add more later. I wish you all a happy use. If you have any questions or suggestions during the use process, you can add my WeChat 252645816 feedback. We also have a dedicated Q&A group to provide free services for you .